
Can the NuExtract Model Extract Tables from Images?

I have been using the NuExtract model to extract tables from images, and I applied the following template:
{
"table": [
{
"table_header": ["string"],
"table_rows": ["string"]
}
]
}
However, the results I received were not as accurate as I hoped for. I wanted to ask if there's a different way to structure the template or modify it to achieve better table extraction results.

Hello, thanks for trying out the model!
For tables, I have found the following to work pretty reliably.
{
"table": {
"header": [
"string"
],
"rows": [
{
"columns": [
{
"column": "string",
"value": "string"
}
]
}
]
}
}
This way the model can kinda break it down into an object hierarchy of table > row > columns/cell values.
Hopefully it works for your use case too!
Otherwise I'd suggest giving some ICL examples or, if the tables follow a similar format, put some prior knowledge of column names etc. in the template.
Hello,
Thanks for the suggestion! I tried the structure you provided, and it works in many cases. However, it tends to extract only the first column reliably. To address this, I found that specifying the column names directly in the template yields better results. Here's an example that worked for me:
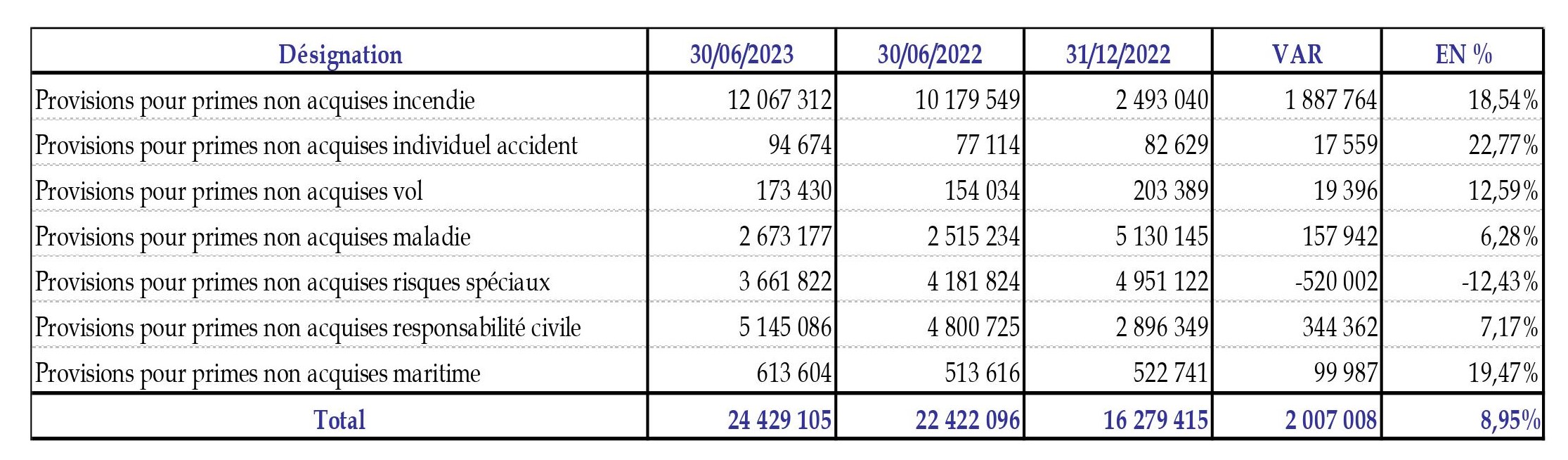
template = """{
"designation": ["string"],
"var": ["number"],
"en%": ["number"],
}"""
Output:
{
"designation": [
"Provisions pour primes non acquises incendie",
"Provisions pour primes non acquises individuel accident",
"Provisions pour primes non acquises vol",
"Provisions pour primes non acquises maladie",
"Provisions pour primes non acquises risques spéciaux",
"Provisions pour primes non acquises responsabilité civile",
"Provisions pour primes non acquises maritime"
],
"var": [
1887764,
17559,
19396,
157942,
-520002,
344362,
99987
],
"en%": [
18.54,
22.77,
12.59,
6.28,
-12.43,
7.17,
19.47
]
}
I also tested it in my notebook, where I evaluated the model on various cases, and it worked well. You can check out the notebook and repository where I test different models and solutions for data extraction, OCR, and structured data extraction from images:
NuExtract-2.8B Structured Data Extraction Notebook
Docs Parsing Techniques Repository